Highway to serv
Je fais une pause dans mes pérégrinations sans fil -principalement parce que je suis pas assez doué pour trouver les infos dont j’ai besoin- et je profite d’un peu de temps libre pour parler réseau.
Comme vous êtes tous nuls dans ce domaine, on va reprendre les bases, et parler d’un des outils les plus connus dans le troubleshoot réseau : traceroute.
Alors, pourquoi je vais parler de ça ?
Tout est parti d’une discussion au boulot dans laquelle je disais “Vous ne connaissez pas le secret de traceroute”. Au final, non, ils ne le connaissaient pas. Et je parie que vous non plus. C’est pour ça que j’ai eu envie d’écrire ce petit post.
C’est parti !
La théorie
Spoiler alert : je vais prendre tout le monde pour des idiots et partir from scratch. Ceux qui veulent esquiver les explications générales, vous pouvez passer au chapitre suivant.
“Bon, traceroute, ça a l’air cool comme nom, mais ça sert à quoi ?”
En quelques mots, c’est un “GPS pour IP”. Ca permet de… tracer sa route en fait :)
L’utilité principale d’un traceroute, c’est de connaitre les équipements intermédiaires entre une machine source et une destination donnée. Par exemple, si je veux savoir le chemin qui me sépare de 8.8.8.8, je vais faire un bête :
$ traceroute 8.8.8.8
traceroute to 8.8.8.8 (8.8.8.8), 30 hops max, 60 byte packets
1 praha-4d-c1-vl55.masterinter.net (77.93.199.253) 0.734 ms 0.805 ms 0.896 ms
2 vl1387.cr3.r1-8.dc1.4d.prg.masterinter.net (83.167.254.150) 0.213 ms 0.226 ms 0.216 ms
3 72.14.214.168 (72.14.214.168) 0.364 ms 0.366 ms 0.394 ms
4 108.170.245.33 (108.170.245.33) 0.273 ms 0.275 ms 0.273 ms
5 216.239.43.73 (216.239.43.73) 0.298 ms 108.170.237.177 (108.170.237.177) 0.298 ms 216.239.62.183 (216.239.62.183) 1.239 ms
6 google-public-dns-a.google.com (8.8.8.8) 0.188 ms * 0.244 ms
Si on regarde un peu plus précisément, on voit que je passe par les machines 77.93.199.253, puis par la 83.167.254.150, etc, pour arriver à la fin à la 8.8.8.8.
“OK, c’est cool, mais je m’en fous de ça moi, ça me sert à rien”
Bah oui, mais non jeune impertinent ! Laisse moi te montrer pourquoi tu es dans l’erreur.
Imaginons un premier cas : tu n’as pas accès aux internets du web. Tu as rebooté ta box, mais rien n’y fait, ça ne fonctionne toujours pas. Et bien, un des tests à effectuer, c’est un traceroute, car ça te permettra de savoir où ça bloque.
En lancant la commande, tu pourras par exemple avoir ce retour :
$ traceroute 8.8.8.8
traceroute to 8.8.8.8 (8.8.8.8), 30 hops max, 60 byte packets
connect: Le réseau n'est pas accessible
L’erreur est ici assez explicite, tu n’as pas accès au réseau. Peut-être as-tu oublié de brancher ton câble wifi ? Peut-être que ton DHCP ne te renvoie pas d’IP ? Peut-être que tu n’as pas de passerelle ? Dans tous les cas, tu n’iras pas loin et ton FAI n’y est pour rien.
Tu pourras aussi avoir cet exemple :
$ traceroute 8.8.8.8
traceroute to 8.8.8.8 (8.8.8.8), 30 hops max, 60 byte packets
1 192.168.1.103 (192.168.1.103) 163.938 ms !H 163.824 ms !H 163.759 ms !H
Là, tu as bien accès au réseau car tu as une IP (la 192.168.1.103), mais tu ne vas pas plus loin. Un problème de passerelle à coup sûr.
Bref, cela te permet de voir d’où vient le souci.
Imaginons maintenant un second cas. Tu es un expert du pentest, et tu dois péter le réseau interne d’un client. En faisant un traceroute depuis le lan user, tu sauras les équipements intermédiaires, et tu pourras ainsi tenter des attaques sur ces équipements, et aussi connaitre les autres réseaux du lan, et tenter de faire du nmap dessus.
Tu vois, jeune impertinent, que traceroute, c’est plutôt pratique. Maintenant, tu n’es plus dans l’erreur.
Le fonctionnement technique
“Bon, ok, ça peut être marrant ton truc, mais comment ça fonctionne ?”
Ahhhh, c’est là qu’on va arriver dans le vif du sujet. Et c’est là que vous allez apprendre un truc ou deux.
Pour comprendre le fonctionnement technique, il faut se pencher un peu sur la RFC IPv4. Ne vous inquiétez pas, elle est pas méchante comparée aux spec 802.11 ^^’
Comme tout protocole, IP est normé et doit suivre un format spécifique qui est le suivant :
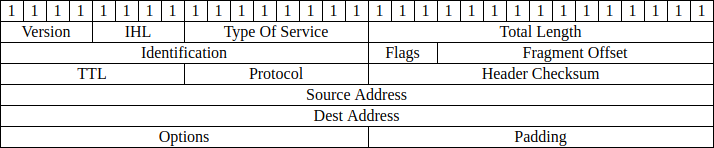
Je vais expliquer rapidement tous les champs, et je m’attarderai ensuite sur le plus important par rapport au traceroute.
- Version : indique la version du protocole. Ici, comme on est en IPv4, c’est “4”. Seems legit.
- IHL : Internet Header Length : la taille de l’en-tête IP, qui ne comprend donc pas la taille du payload des couches OSI supérieures.
- TOS : Type Of Service : permet de définir si un paquet doit être priorisé ou non. C’est de la QoS version light.
- Total length : taille du datagramme, qui correspond à l’IHL + le payload. Attention, on ne compte pas les couches inférieures (la partie MAC par exemple). En général, je dis toujours paquet, peu importe la couche, mais là, j’ai bien utilisé le terme datagramme car la différence est importante. (un paquet, c’est totalité des couches, le datagramme non).
- Identification : un ID quoi :)
- Flags : Permet de savoir si le message envoyé est fragmenté en plusieurs paquets.
- Fragment offset : permet de savoir à quelle partie du fragment d’un message correspond ce paquet. Evidemment, ça dépend du flag.
- TTL : Time To Live : Temps avant que le paquet ne soit considéré comme périmé.
- Protocole : indique le protocole de la couche supérieure (TCP, UDP, etc).
- Header Checksum : un bête checksum pour valider que l’en-tête IP n’aie pas été corrompu durant le transport.
- Source/Destination addresses : Les IP source et destination.
- Options : bahhhh, des options quoi ^^ Ca permet d’ajouter des infos sur l’en-tête IP au besoin.
- Padding : un paquet de 0 à la fin de l’en-tête IP, afin qu’il soit un multiple de 32.
Peut-être que je ferais un article plus poussé sur IP un jour. Ou peut-être pas. En tout cas, vous voyez un peu l’idée du truc.
Mais revenons à nos moutons : le champ qui nous intéresse réellement ici est le TTL, et je vais donc expliquer plus précisément son fonctionnement.
C’est un champ codé sur 8 bits, qui peut donc aller de 0 à 255. Lorsque ma bécane envoie un paquet IP (soit la très grande majorité des paquets), mon OS va mettre le champ TTL à une valeur donnée (ça dépend de l’OS, du kernel et du temps qu’il fait dehors), mais il ne faut pas qu’il soit trop petit, sous peine que le paquet n’arrive jamais à destination.
“Comment ça, ‘n’arrive jamais à destination’ ?”
Tu n’écoutes rien jeune impudent. J’ai dit quoi sur le TTL ? Hein ? J’ai dit quoi ? Que c’est le “temps avant que le paquet ne soit considéré comme périmé”. Avec un TTL trop court, ton paquet paquet sera bon pour la poubelle avant d’arriver à bon port.
A chaque machine intermédiaire, le TTL va être décrémenté d’un. Pour être plus précis, il va être décrémenté d’autant de secondes qu’il reste sur cette machine intérmédiaire. Mais dans la pratique, c’est toujours inférieur à la seconde, donc on réduit d’une seule unité.
Attention, quand je dit “machine intermédiaire”, ce ne sont pas TOUTES les machines intermédiaires. Ce sont toutes les machines intérmédiaires qui LISENT l’en-tête IP. Un switch par exemple, il s’en cogne de cet en-tête, puisqu’il s’arrête à la couche d’en dessous. Ainsi, on considère que les machines intermédiaires sont celles qui connectent des réseaux entre eux : les routeurs (ou assimilé).
Pour info, le TTL a été mis en place pour éviter d’avoir des paquets qui tournent en boucle à l’infini.
“‘Qui tournent en boucle’ ?”
Exactement. Tu peux avoir des cas où un paquet est envoyé par un routeur A vers un routeur B et ledit routeur B le renvoie au routeur A. Si le TTL n’existait pas, les deux équipements se renverraient en permanence la balle (Qui à dit DoS ? :D )
Du coup, quand le TTL arrive à 0, il est tout simplement envoyé au cimetière des paquets (RIP).
“Ouais ouais, c’est cool ton histoire là, mais il est où le rapport ?”
Le rapport ? Et bien comme les routeurs sont gentils, ils nous préviennent quand un paquet est droppé à cause du TTL, grâce à un paquet ICMP, de type 11 et de code 0. (Pour ceux qui ne connaissent pas trop ICMP, les types sont grosso modo l’équivalent des ports TCP ou UDP).
Tu commences à voir le rapport, jeune éffronté ?
Imagine que j’envoie un paquet avec un TTL de 1. Quand il va arriver au premier équipement, le champ va être décrémenté. Il tombe donc à 0, le routeur va dropper le paquet et me prévenir via un ICMP/11/0 qu’il a exterminé le paquet. Comme ça, je connais la première machine intermédiaire.
Imagine ensuite que j’envoie un second paquet, avec un TTL de 2. Arrivé au premier équipement, le TTL passe à 1, puis est renvoyé ver le routeur suivant. Encore une fois le TTL est décrémenté et tombe à 0. Le second routeur va donc anihiler le paquet puis me prévenir.
Ainsi en envoyant plusieurs paquets avec un TTL de plus en plus grand, on peut retrouver le chemin complet vers une machine.
Au passage, suite à l’écriture de cet article, on m’a demandé pourquoi on pouvait voir des étoiles dans certains retours traceroute, dans ce genre là :
traceroute -n poul.pe
traceroute to poul.pe (91.121.196.223), 30 hops max, 60 byte packets
1 192.168.1.1 2.191 ms 2.239 ms 2.390 ms
[...]
8 94.23.122.146 53.839 ms 88.330 ms 88.112 ms
9 * * *
10 94.23.122.73 87.063 ms 87.058 ms 88.317 ms
11 * * *
12 * * *
En fait, c’est tout à fait logique. Si on regarde le détail de la RFC 792, on voit ceci : “If the gateway processing a datagram finds the time to live field is zero it must discard the datagram. The gateway may also notify the source host via the time exceeded message.”. Donc, les routeurs ne sont pas dans l’obligation de nous prévenir. Dans ce cas, traceroute sait qu’il y a un équipement, mais ne peut pas trouver son IP, puisque l’équipement ne répond rien. La même situation peut se produire si un firewall bloque le traceroute.
Les outils
Sur windows, c’est simple, on a tracert, épicétou.
Sur linux par contre, on a traceroute et tracepath. Et c’est en partie pour cela que je me suis mis à écrire cet article : c’est quoi la différence entre les 2 ?!
En fait, traceroute peut avoir besoin d’ouvrir des raw sockets. Et les raw sockets, en général, ça a besoin des droits root. A l’inverse, tracepath n’ouvre pas ses sockets en raw, donc pas besoin du root :)
A coté de ça, en regardant les sources et les man, on voit 2 choses : traceroute a clairement plus d’options que tracepath, mais ce dernier vérifie (et modifie au besoin) la MTU (Maximum Transmission Unit, la taille maximum qu’un paquet peut avoir). Pratique quand on passe sur de l’IPSEC ou du MPLS.
Sinon, bahhhh, ça va pas beaucoup plus loin en fait au niveau différences. ^^’ C’est un peu décevant, je vois pas trop l’intéret d’avoir deux outils quasiment identiques (surtout qu’ils sont tous les deux installés par défaut dans certaines distros).
Au passage, s’il y a une option à connaitre sur ces outils, c’es le “-n” (“-d” sur windows) qui évite de faire une résolution DNS inverse sur les IP trouvées. Parce qu’honnêtement, je n’ai jamais eu besoin des NDD associées aux IP pendant un traceroute.
Le secret de traceroute :)
Au début du post, j’ai parlé d’un secret, et puis plus j’ai avancé dans l’article, plus je me suis rendu compte qu’il était quasiment inutile ^^’
Quand on fait un traceroute, à moins de s’y intéresser vraiment, on sait pas trop comment ça fonctionne under the hood. On sait que ça utilise le TTL, mais c’est tout.
Ce qu’il faut prendre en compte, c’est que le protocole IP a besoin pour fonctionner du champ Protocol (qui, pour rappel, définit le proto de niveau supérieur). Ce champ est donc un ID qui renvoie à une liste définie par l’IANA.
Et bah, le secret, c’est que sur windows, ça utilise de l’ICMP (ID 1) et sur linux de l’UDP (ID 17) :D
“Quoi, c’est tout ? C’est juste ça ton secret ?”
Bah oui ^^’ Et le truc dans l’histoire, c’est qu’avant d’écrire cet article, je trouvais ça marrant, mais au final, c’est totalement inutile puisqu’on se sert d’un champ du proto IP pour cet outil, donc au final, peu importe la couche supérieure, ça ne change absolument rien (en fait si, les firewalls auraient fait la gueule avec des trucs exotiques).
J’ai cherché une explication plus détaillée sur le fait d’utiliser ICMP sur win et UDP sur nux, mais je n’ai trouvé de solution qui me plaise.
L’idée la plus probable, c’est que comme nux a besoin d’être root pour envoyer des paquets ICMP (si, si, promis, regardez le setuid de la commande ping :) ), les devs de traceroute ont utilisé de l’UDP pour éviter d’avoir à setuid le programme. Mais bon, c’est un peu naze comme explication, puisqu’il existe une option pour faire un traceroute avec de l’ICMP (d’où les raw sockets dont je parlais plus haut.), et donc, faut avoir les droits root. De plus, ping est setuid, donc bon, les mecs de chez linux auraient très bien setuid traceroute aussi.
Conclusion
Voilà, petit article rapide, qui permet de comprendre un peu ce qu’est traceroute et son intérêt. J’espère qu’il vous aura fait prendre que le réseau cétrocoul et que vous voulez tous devenir ingé réseau maintenant :D
Plus sérieusement, si vous avez appris quelque chose, c’est le plus important ;)
Oh, et si jamais quelqu’un sait réellement pourquoi UDP par défaut sur nux, qu’il n’hésite pas à me le dire !
Enjoy
The lsd
Liens
Lame-Socket-Dispatcher : un script en python pour faire un traceroute. C’est un POC, rien de plus.