Pwning N64 for fun & speedrun : MIPSWTFR4300iLOL
Salut les chamallowsmous,
Je sais que je me suis fait une petite spécialité dans l’analyse du 802.11, mais comme je suis en voyage, c’est pas toujours facile d’analyser du wifi. Du coup, à la place, je me suis lancé dans le rom hacking. Alors, késséca le rom hacking ? Et puis pourquoi je fais ça ?
Le rom hacking, c’est globalement la modification d’une rom (je vous fais pas l’insulte de vous expliquer ce qu’est une rom hein) pour ajouter, modifier ou supprimer des éléments. Par exemple, rendre le jeu plus difficile en ajoutant des ennemis, ou ce genre de trucs. Ça se fait pas mal sur des jeux 2D (NES, megadrive, etc), parce que c’est plus simple (pas de gestion de la 3D, archi basique, blablabla).
Pourquoi je fais ça, me direz vous ? J’suis en voyage pour plusieurs mois, j’ai d’autres choses à foutre.
Baahhhh quand il y a 15 heures ou plus de trajet, sans internet, faut bien passer le temps, et regarder par la fenêtre, ça va bien 5 minutes :D.
Pour la petite histoire, j’ai retrouvé, juste avant mon départ, ma N64 avec un de mes jeux préférés : Star Wars Shadows Of The Empire. Un jeu un peu pourri, pas facile à jouer, mais j’étais gosse et c’était mon premier jeu N64 :).
Du coup, je me suis amusé à le refaire, et à tenter de le speedrunner. Problème : j’y connais rien speedrun, et j’suis nul à chier, donc j’arrive pas à grand chose. Par contre, je suis pas (trop) mauvais en informatique. Donc dans ma petite tête ça a fait “HEYYYY, MAIS T’AS QU’A TROUVER DES BUGS DANS LE JEU POUR GLITCHER”. Et boom, il en a pas fallu plus pour que je me lance dans ce projet !
Bref, assez parlé de moi, vous voulez pas un journal intime, vous voulez de la technique.
So, let’s go motherfuckers !
Environnement
Shadows Of The Empire (je vais l’appeler SOTE hein, ça sera moins galère à écrire) est un jeu nintendo 64, sorti en 1996, et édité par LucasArt. Il est sorti un peu plus tard sur PC (mais on a pas le droit d’utiliser la version PC pour le speedrun). On y joue Dash Rendar, un mercenaire pote de Yan Solo (oui je dis Yan), dans une histoire qui se passe entre l’épisode 5 et 6. Assez de digression, et place à la mise en place de mon environnement.
Nintendo 64 oblige, j’ai du installer un émulateur. Nemu64 a très bonne réputation pour son debuggueur, moins pour son émulation. Après plusieurs tests, j’ai abandonné parce que le jeu ne fonctionnait pas correctement, et switché pour Project64. Heureusement, un mec sûrement plus doué que moi a forké P64, pour y intégrer un debuggueur digne de ce nom. La team de P64 a récemment intégré ce debuggueur dans la branche master, donc j’ai accès à un truc nickel !
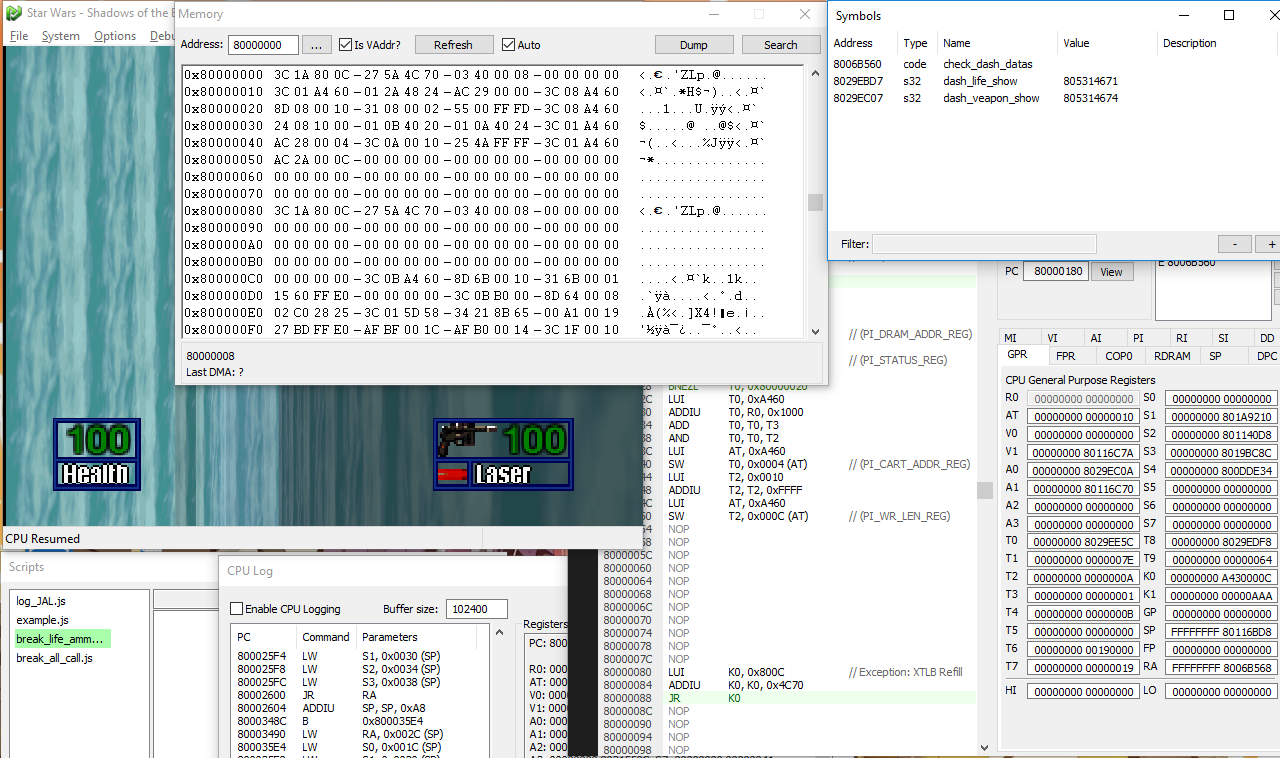
Globalement, on retrouve les fonctionnalités basiques d’un debuggueur. Je vais faire une passe rapide sur les parties importantes.
La fenêtre Commands
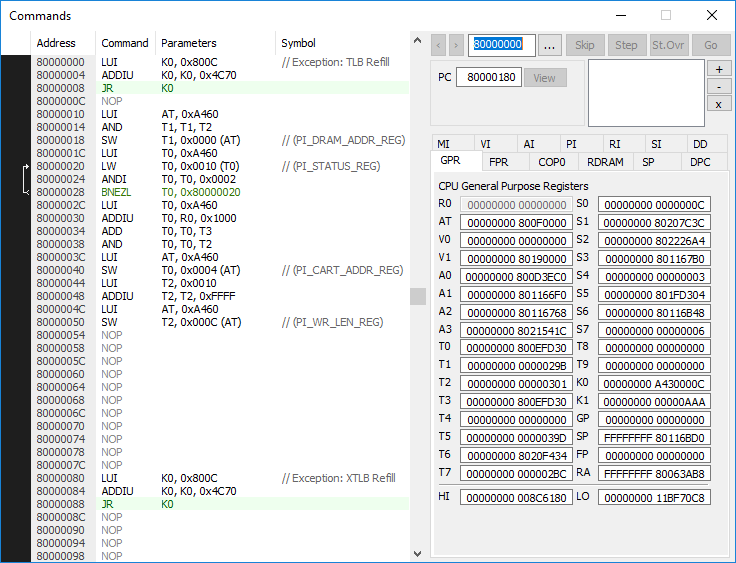
Ce sont les instructions ASM (j’en reparle plus loin). On a sur le coté gauche la liste des instructions en cours, et à droite la liste des registres (il y en a un paquet, bien plus que sur une archi x86) et quelques trucs utiles, genre les breakpoints :).
Cette fenêtre est la plus utile de toutes, mais elle reste basique : on ne peut pas faire de recherche d’opcodes, le scroll est super chiant, et il manque des infos utiles (genre l’affichage du contenu d’une adresse).
La fenêtre Memory
C’est la heap qu’on retrouve classiquement sur toutes les archis. On se croit dans matrix quand on regarde la heap se modifier en temps réel quand je jeu tourne. Il y a possibilité de dumper tout ou partie de la mémoire (attention, c’est moitié buggué though).
La fenêtre Symbols
Bah oui, la rom est pas compilée avec les symbols. Du coup, on doit se les créer à la mano. C’est un peu bordélique, mais ça fonctionne :).
La fenêtre CPU logs
Je m’en suis servi quelques fois, pas super pratique à utiliser parce que bon, soyons clairs, les instructions défilent vite, mais ça peut être pas mal pour analyser une action en particulier (appui sur une touche, tir de pistolet).
La fenêtre Scripts
Mine de rien, elle m’a été super pratique une paire de fois ! Le debuggueur inclut une API (minimaliste certes, mais quand même) qui permet d’automatiser certaines tâches. De plus, on est obligé de passer par là pour certaines actions, comme l’automatisation de BreakPoints. Bref. Faut toujours l’avoir dans un coin :).
radare2
La N64 n’utilise pas un proc x86, donc je peux oublier ollydbg, et j’ai pas d’IDA pro sous la main. Du coup, j’ai un radare2 qui tourne et surtout qui comprend l’archi N64. Ca me permet de pallier à certains manques du debuggueur builtin de P64 (au hasard, la recherche d’opcodes). Etant daubé en radare2, je l’ai pas encore utilisé plus que ça.
L’achitecture
OK, c’est cool, j’ai présenté le tool dont je me sers et tout. Mais ça reste un tool. Pour pouvoir rom hacker, il faut comprendre le fonctionnement d’une N64, c’est un peu plus important.
Du coup, cékoicebordeldeN64 ?
Le proc principal
La N64 embarque une proc 64 bits, cadençé à 93.75Mhz créé par MIPS Technologies. Ce proc est connu sous le nom de VR4300. C’est une version dérivée du R4300i, lui même dérivé du R4200, qui comprend certaines modifications que je ne maîtrise absolument pas. La seule différence notable que j’ai pu remarquer est l’utilisation d’opcodes non définis dans un MIPS classique (BEQZ par exemple, mais qui sert juste de raccourci pour une autre instructions).
Pour ceux qui veulent plein de détails techniques imbitables, la datasheet est dispo.
Le Reality CoProcessor
Pour gérer la vidéo et l’audio, Nintendo a fait le choix (utile) de mettre en place un proc dédié, qu’ils ont sobrement appelé le “Reality Coprocessor”. Il se divise en 2 parties, le RSP (Reality Signal Processor) et le RDP (Reality Display Processor).
Cela dit, comme ce coproc sert principalement à gérer l’affichage, on s’en fout un peu pour le moment. On le tâtera peut être quand il faudra jouer avec les textures ou quoi, mais j’ai pas envie de m’amuser à bidouiller les calculs 3D.
La RAM
Nintendo a inclus dans sa console 4.5mo de RAM (dont 0.5 pour l’antialiasing, apparemment). Rien de plus à dire, c’est de la ram quoi…
Là où ils ont bien joué leur coup, c’est en proposant à l’achat l’expansion pack, qui permet de rajouter 4mo de ram supplémentaire. Obligatoire pour certains jeux, évidemment, par exemple Zelda Majora’s Mask.
IMAGINEZ VOUS, LE JOUR DE NOEL, RECEVOIR ZELDA MAJORA’S MASK EN CADEAU, SANS AVOIR L’EXPANSION PACK. VA TROUVER UN MAGASIN OUVERT ! MERCI NINTENDO. TU AS GÂCHÉ MON NOEL.
L’archi MIPS
Je passe un coup là dessus, car c’est plutôt important. On est sur une archi bien différente d’un x86, donc il est important de comprendre certains concepts basiques.
L’instruction Set
MIPS est une architecture RISC. Ce qui est bien avec le R dans RISC, c’est que ça veut dire “Reduced” Donc qu’il n’y a pas des milliards d’opcodes différents :D
Plus important cela dit, la liste des opcodes se trouve ici. On notera que chaque instruction se fait sur 4 octets, ce qui facilite les calculs :)
Globalement, on retrouve ces deux opcodes très souvents, dont je parle plus loin. Je ferais un blogpost à part pour lister les autres opcodes importants :
- JAL : Jump And Link
- JR : Jump Return
Il existe également un instruction set “spécial”, qui est utilisé uniquement pour les registres FX (les floating points). Ils sont un poil tordus car ils sont en fait “variables”.
Par exemple :
c.lt.sc.gt.sc.eq.d
font parties de la même famille. Il faut les lire comme
Compare | Less Than/Greater Than/EQual register X, register Y | as Single/Double.
De ce que j’en sais (c’est à dire pas tant que ça), on ne peut pas travailler sur des registres généraux et floating en même temps. Faire un multu t0, f4 n’est -à priori- pas possible.
Il faut donc utiliser des instructions pour envoyer les valeurs d’un registre général vers un floating (LWC, MTC par exemple). Une fois que les opérations coproc sont faites, on utilise d’autres instructions (SWC, MFC) pour récupérer une valeur d’un registre floating.
Les registres
“Et bah putain !” On a 32 registres différents pour les généraux. Petite passe rapide :
- R0 : simple. Il vaut zéro. Toujours. No exception.
- AT : registre temporaire, il est utilisé un peu pour tout et n’importe quoi. En général, sa valeur est utile pour quelques instructions et elle est droppée après.
- V0 et V1 : généralement, les valeurs de retour d’une fonction.
- A0 -> A3 : généralement, les arguments passés à une fonction.
- T0 -> T9 : des registres temporaires. Mais un peu moins que AT. Une fonction appelée se tape royalement de ce qu’il y a dedans et peut les modifier à l’envie.
- S0 -> S7 : les registres de sauvegarde, qui ne doivent théoriquement pas être modifiés dans le corps d’une fonction. Ils permettent de sauvegarder les infos en passant d’une fonction à une autre.
- K0 et K1 : Réservé au kernel. Fopatouché. (‘fin… j’ai bien envie quand même x) ).
- GP : le Global Pointer. A priori, il sert pour toutes les valeurs statiques, genre des variables globales ou un truc du genre. Il est pas réellement utilisé dans le code.
- SP : le Stack Pointer, qui sert à savoir où on en est niveau… bah de la stack quoi :D On y met la dernière adresse connue de la stack ici.
- FP : Frame Pointer. Dans la pratique, on s’en balec, il est pas réellement utilisé.
- RA : Return Address, c’est le registre qui permet d’enregistrer l’adresse de retour du dernier call. J’explique le détail plus loin.
On a aussi des registres spéciaux :
- PC : Program Counter. Il sert bêtement à connaitre l’adresse de l’instruction en cours.
- HI/LO : On met ici le résultat de certaines instructions (multiplications et divisions par exemple).
On a aussi 32 registres pour le coproc 0. Ils doivent sûrement servir à quelque chose. On verra plus tard.
Il existe aussi d’autres registres, notés FX (X allant de 0 à 32). Ils sont utilisés par le coproc 1, pour tout ce qui est floating point (les instructions “spéciales” expliquées plus haut).
Enfin, il y a des registres pour les interfaces “physiques” (disque, serial, audio, etc.), mais on verra ça plus tard, je dois encore potasser le fonctionnement :)
Et pour ceux qui se posent la question, il n’y a pas de registre pour les flags. C’est géré autrement, mais j’en parlerai dans l’article suivant.
Le delay branch
Encore un truc qui n’existe pas en x86. Pour expliquer simplement, pour chaque instruction en assembleur, il y a plusieurs étapes (lecture, analyse, blablabla) pour exécuter l’opcode. Et pour être le plus “efficace” possible, c’est plus ou moins parallélisé.
En gros, on va lire l’instruction 1 (l’étape 1), puis passer à son analyse (l’étape 2).
“Pendant” que l’instruction 1 est analysée, l’instruction 2 va passer en phase de lecture (étape 1 pour cette nouvelle instruction). Du coup, quand on fait un jump, il est déjà trop tard, l’instruction 2 est déjà dans le pipeline et doit être finalisée (avec les étapes 2 à 5). Un bon schéma des familles permettra de comprendre plus facilement.
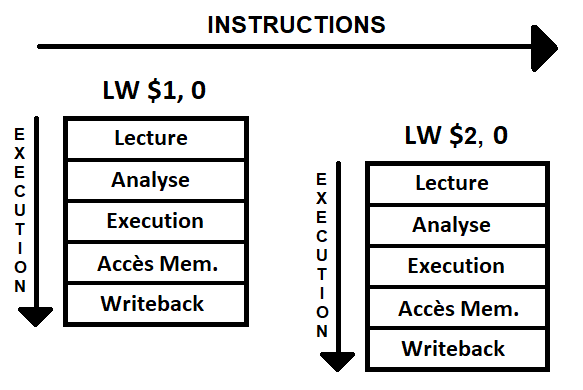
Par exemple, si on a :
001 LW $1 0 // on met 0 dans $1
002 LW $2 1 // on met 1 dans $2
003 BEQ $1, 0, 005 // si $1 vaut 0, on va en 0005
004 ADD $1, $1, $2 // on incrémente $1. En x86, cet opcode n'est jamais appelé en raison du BEQ. en MIPS, il l'est.
005 ADD $1, $1, $2 // on incrémente $1, encore une fois.
$1 vaudrait… 2 \o/.
Pour ceux qui veulent vraiment comprendre, c’est lié au pipelining de l’archi MIPS. Mais, c’est pas le sujet du jour, je pondrais peut être un article dessus une autre fois ^^.
Ce qui est étonnant, c’est que sur le r4300i, il existe des instructions Branch qui permettent d’éviter ce branch delay (celles qui se terminent par un L). Comment ? Pourquoi ?
En fait, le L signifie “Likely”. Le compilo décide pour whatever reason qu’il y a de nombreuses chances que la branche soit prise, donc il optimise et n’exécute pas l’instruction juste derrière la branche. Ca vous rappelle rien ? https://meltdownattack.com/ ? :D
Les calls
Sur une archi MIPS, les calls en tant que tels n’existent pas. A la place, on a l’instruction JAL (Jump And Link) qui fait mas o menos la même chose.
Un JAL va aller vers une adresse et mettre dans le registre RA l’adresse de retour (donc l’adresse du JAL+8). Pourquoi +8 ? En raison du Branch Delay : l’instruction en JAL+4 étant techniquement exécutée AVANT le JAL.*
A la fin de la fonction, on va avoir un JR RA qui va permettre de revenir à la fonction appelante (ou au main, whatever). C’est l’équivalent d’un RET en x86.
Pour ceux qui réfléchissent 2 secondes, on voit vite un problème.
Si on appelle une fonction à l’intérieur d’une fonction ? On a 2 JAL imbriqués. On la sauvegarde où l’adresse de retour du 2eme JAL ? Dans le RA ? Bah non, on va perdre l’adresse du premier JAL :D En fait, on va utiliser plus ou moins… ce qu’on veut. Un autre registre, la stack, un poulpe, peu importe.
Par convention, en début de fonction, on sauvegarde RA dans la stack, et on le repousse en fin de fonction, afin de toujours utiliser un JR RA pour revenir à la fonction appelante. Mais c’est juste une convention, on pourrait très bien faire un JR T0 par exemple.
Les conventions
D’ailleurs, en parlant de conventions, ce n’est que ça sur MIPS.
Par exemple, certains registres sont sauvegardés par l’appelant, et d’autres par l’appelé (qui doit tout remettre en ordre à la fin). Mais selon les conventions, les registres à sauvegarder peuvent être différents.
Dans le même ordre d’idée, il existe une convention au niveau des registres : dans celle-ci il existe 8 registres pour les arguments, et non 4 comme j’ai présenté plus haut. Mais c’est pas toujours le cas. Parce qu’il en existe plusieurs, des conventions…
D’une manière générale, il faut juste espérer que les mecs avec qui tu bosses ont la même convention que toi, sinon, tu peux être sûr que ça va merder.
Sur N64 cela dit, les specs données par Nintendo sont précisées, et normalement, les devs la respectent.
Quelques tricks
A force d’analyser SOTE, j’ai pu remarquer plusieurs tricks utilisés fréquemment, qui servent à gagner en perf ou en temps.
Histoire que personne d’autre ne perde de temps à essayer de comprendre le pourquoi du comment, je vous les donne gratuitement :D
Copier un registre
La manière la plus simple de copier un registre, et ça se fait en une seule instruction, c’est comme ça :
OR dest, src, R0 // R0 correspond toujours à 0 :)
Du coup, comme on fait un OR 0, ça revient juste à copier tous les bits de src, vers dst.
Charger/Sauver une data.
Comme tout instruction set digne de ce nom, on peut récupérer une data de la heap, ou la mettre dedans, mais on ne peut pas le faire directement (genre un MOV data, addr). On doit donc utiliser un registre. La manière la plus rapide de le faire est comme ceci :
LUI AT, 0x800D // Load Upper Immediate
LW A0, 0x5B40(AT) // Load Word
Les registres font 64 bits, mais ils sont utilisés en mode 32b (dans SOTE en tout cas). Faut prendre ça en compte niveau MSB (Most Significant Bit) / LSB (Least Significant Bit), et donc les parties hautes et basses du registre.
LUI correspond à “Mets moi cette valeur dans la partie haute du registre X”. Les plus petits bits sont settés à 0.**
AT va donc correspondre à 800D0000.
Le LW va ensuite dire “Enregistre moi dans A0 la valeur à AT+X”, X étant le décalage voulu.
Du coup, si on “résume” l’instruction, cela correspond à :
SW A0, 0x800D000 + 0x5B40 // donc 0x800D5B40
Pourquoi on ne peut pas utiliser directement d’adresse, me demanderez vous ? Ma supposition (plutôt logique, à priori), c’est que chaque instruction étant codée sur 4 octets, on ne peut pas mettre en argument une addresse qui se placerait dans une seule instruction : on peut au plus mettre 2 octets, ce qui n’est pas suffisant. On doit donc utilise ce trick
Passer d’un Word à un HWord
Il est fréquent de forcer une variable à une taille précise (passer d’un DWord à un Word, d’un Word à un HWord, whatever). En 2 instructions, on peut le faire, à grands coups de marteau ^^.
SLL T1, T0, 16 // shift left logical
SRA T0, T1, 16 // shift right arithmetic
En gros, on décale la valeur de T0 de 16 bits vers la gauche, puis on la redécale de 16 bits vers la droite.
Si T0 vaut par exemple 01234567, on va le shifter de 16 bits (donc 4 octets) vers la gauche. Il correspondra donc à 45670000.
En le reshiftant à droite de 16 bits (toujours 4 octets hein, ça a pas changé), il va passer à 00004567. Ici, on est donc passé d’un Word à un HWord. En pseudo-code, ça donnerait ça :
double_var = 12345678912345678
int_var = (int)double_var
Maintenant que tout est prêt, LET’S ROMHACK ! (mais au prochain blogpost)
Enjoy
The lsd
Sources
- infrid.com : un petit repo contenant des liens utiles sur MIPS et la N64
- ultra64.ca : la doc technique du R4300
- en64.shoutwiki.com : une perle ! On trouve pas mal d’infos sur le fonctionnement MIPS. Je l’ai trouvé sur le tard, mais il est super utile !
- github.com : un listing des intructions MIPS. Vous en faites pas, je vais faire un article à part là dessus.
* Pourquoi toujours 4 et 8, et pas 1, 2, ou autre ? Remember ? Les instructions sont codées sur 4 octets. Faut écouter quand on parle :p
** On fait un left shift en fait :)